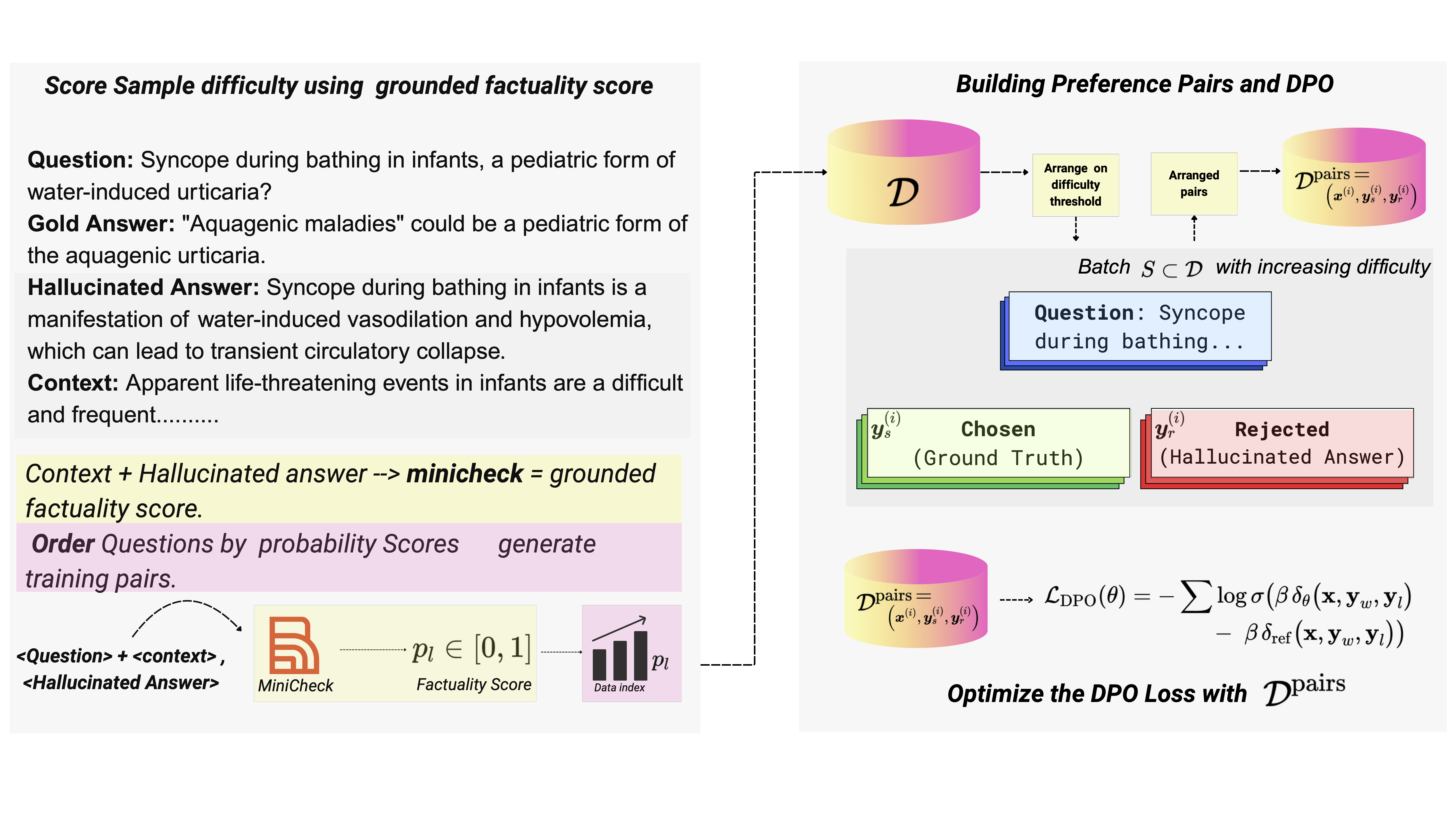
Aligning large language models (LLMs) to accurately detect hallucinations remains a significant challenge due to the sophisticated nature of hallucinated text. Recognizing that hallucinated samples typically exhibit higher deceptive quality than traditional negative samples, we use these carefully engineered hallucinations as negative examples in the DPO alignment procedure. Our method incorporates a curriculum learning strategy, gradually transitioning the training from easier samples, identified based on the greatest reduction in probability scores from independent fact checking models, to progressively harder ones. This structured difficulty scaling ensures stable and incremental learning. Experimental evaluation demonstrates that our HaluCheck models, trained with curriculum DPO approach and high quality negative samples, significantly improves model performance across various metrics, achieving improvements of up to 24% on difficult benchmarks like MedHallu and HaluEval. Additionally, HaluCheck models demonstrate robustness in zero-shot settings, significantly outperforming larger state-of-the-art models across various benchmarks.
Teaching with Lies
Curriculum DPO on Synthetic Negatives for Hallucination Detection
Shrey Pandit*† , Ashwin Vinod† , Liu Leqi , Ying Ding
The University of Texas at Austin
*Corresponding author | †Equal contribution